AdapterDrop: On the Efficiency of Adapters in Transformers
Our Contributions
- We establish the computational efficiency of adapters compared to full fine-tuning. We find that Adapters can train 60% faster than full fine-tuning. With AdapterDrop we increase inference speed by up to 36% for 8 parallel tasks.
- With our robust AdapterDrop layers, we improve the efficiency of adapter models during training and inference. By removing adapters from lower layers, based on available computational resources, we enable a dynamic trade-off between inference speed and task performance.
- We also reveal significant potential for boosting the efficiency of AdapterFusion. We can drop the majority of adapters after transfer learning from the Fusion model, while maintaining task performance entirely.
Adapters vs. Full Fine-tuning
We show that the training steps of adapters are up to 60% faster than full model fine-tuning with common hyperparameter choices, while only being 4–6% slower during inference (see Table 1 below). The training speedup can be explained through decreased overhead of gradient computation. Most of the parameters are frozen when using adapters and it is not necessary to backpropagate through the first components (see Figure 1 below).
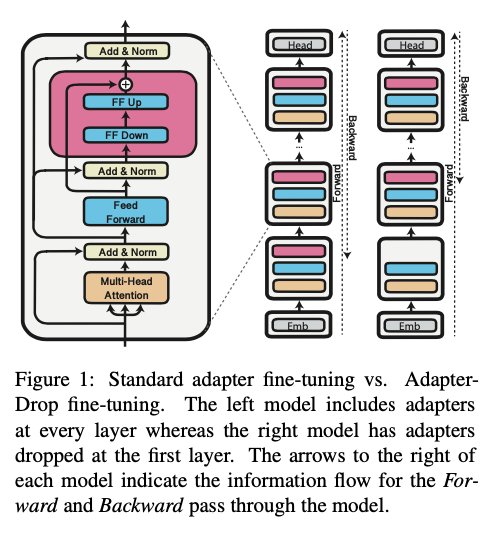

Adapter Drop
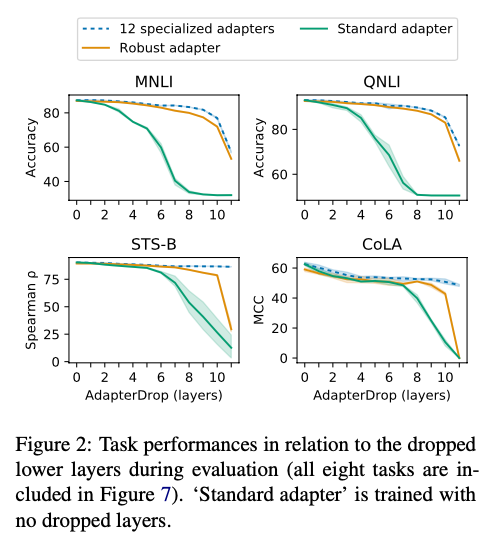
We propose AdapterDrop, the efficient and dynamic removal of adapters from lower transformer layers at training and inference time, resulting in more efficient adapter-based models that are dynamically adjustable regarding the available computational resources (depicted in Figure 1 above). We show that dropping adapters from lower transformer layers considerably improves the inference speed in multi-task settings. For example, with adapters dropped from the first five layers, AdapterDrop is 39% faster when performing inference on 8 tasks simultaneously. At the same time, we largely maintain the task performances even with several dropped layers (see Figure 2 below).
AdapterFusion, Cross-Layer Parameter Sharing, and More!
In our paper, we include several other interesting findings:
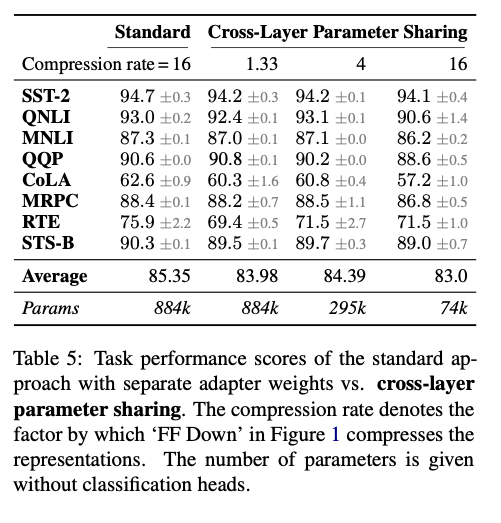
- We find that we can share the adapter weights across all layers without losing much performance. This drastically reduces the storage space required for each task even further (see Table 5 below).
- We compare randomly initialized adapters with MLM pre-training for adapters, and find no significant differences.
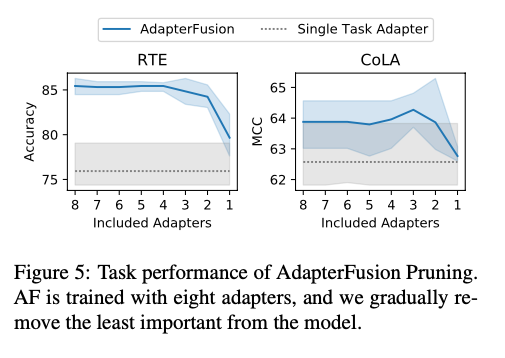
- We prune adapters from adapter compositions in AdapterFusion and retain only the most important adapters after transfer learning, resulting in faster inference while maintaining the task performances entirely (see Figure 5 below).
Abstract
Massively pre-trained transformer models are computationally expensive to fine-tune, slow for inference, and have large storage requirements. Recent approaches tackle these shortcomings by training smaller models, dynamically reducing the model size, and by training light-weight adapters. In this paper, we propose AdapterDrop, removing adapters from lower transformer layers during training and inference, which incorporates concepts from all three directions. We show that AdapterDrop can dynamically reduce the computational overhead when performing inference over multiple tasks simultaneously, with minimal decrease in task performances. We further prune adapters from AdapterFusion, which improves the inference efficiency while maintaining the task performances entirely.
Bibtex
@article{rueckle-etal-2020-adapterdrop,
title = "{AdapterDrop}: On the Efficiency of Adapters in Transformers",
author = {R{\"u}ckl{\'e}, Andreas and
Geigle, Gregor and
Glockner, Max and
Beck, Tilman and
Pfeiffer, Jonas and
Reimers, Nils and
Gurevych, Iryna},
journal = {arXiv},
year = {2020},
url = "https://arxiv.org/abs/2010.11918"
}