MultiCQA: Zero-Shot Transfer of Self-Supervised Text Matching Models on a Massive Scale
Our Contributions
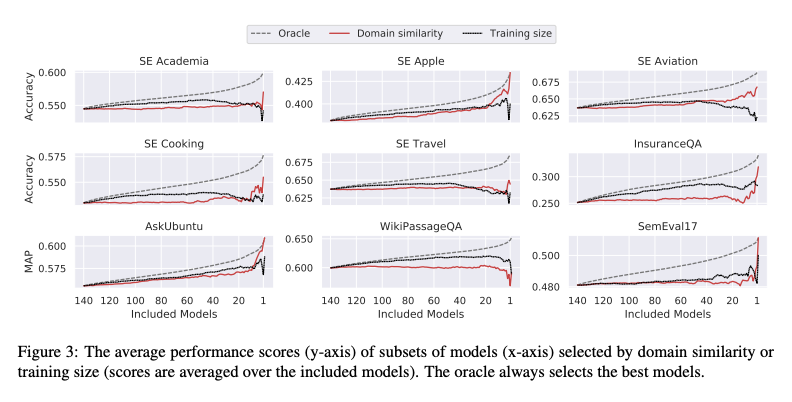
- We train 140 models on different domains and surprisingly find that neither domain similarity nor data size are critical factors for the best zero-shot transferability.
- The majority of our 140 models outperforms common IR baselines on non-factoid answer selection and question similarity tasks. We show that our training stragy yields models that transfer well, even across distant domains.
- Our zero-shot MultiCQA model incorporates self-supervised and supervised multi-task learning on all source domains, and outperforms in-domain BERT and RoBERTa on six evaluation benchmarks.
Zero-Shot Transfer from 140 Source Domains
The following shows the task performances of all 140 models to our nine evaluation datasets.
By investigating such a large number of models, we can provide insightful analyses based on our large sample size. We investigate whether more similar domains or larger source datasets lead to better zero-shot transferability:
Abstract
We study the zero-shot transfer capabilities of text matching models on a massive scale, by self-supervised training on 140 source domains from community question answering forums in English. We investigate the model performances on nine benchmarks of answer selection and question similarity tasks, and show that all 140 models transfer surprisingly well, where the large majority of models substantially outperforms common IR baselines. We also demonstrate that considering a broad selection of source domains is crucial for obtaining the best zero-shot transfer performances, which contrasts the standard procedure that merely relies on the largest and most similar domains. In addition, we extensively study how to best combine multiple source domains. We propose to incorporate self-supervised with supervised multi-task learning on all available source domains. Our best zero-shot transfer model considerably outperforms in-domain BERT and the previous state of the art on six benchmarks. Fine-tuning of our model with in-domain data results in additional large gains and achieves the new state of the art on all nine benchmarks.
Bibtex
@inproceedings{rueckle-etal-2020-multicqa,
title = "{MultiCQA}: Zero-Shot Transfer of Self-Supervised Text Matching Models on a Massive Scale",
author = {R{\"u}ckl{\'e}, Andreas and
Pfeiffer, Jonas and
Gurevych, Iryna},
booktitle = "Proceedings of The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP-2020)",
year = "2020",
address = "Virtual Conference",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.194",
pages = "2471--2486",
}