Neural Duplicate Question Detection without Labeled Training Data
Our Contributions
- We study how to best train duplicate question detection models and propose two novel training methods that only require unlabeled question title-body pairs from cQA forums.
- Both our methods, duplicate question generation and weak supervision with title-body pairs, can utilize large amounts of unlabeled data, which often achieves better performances compared to other techniques.
- Surprisingly, we also find that question generation models for duplicate question generation transfer well, even across distant domains.
- We show that our methods are also suitable for training answer selection models without direct question-answer supervision. They can, thus, have a wider impact beyond duplicate question detection.
Duplicate Question Generation
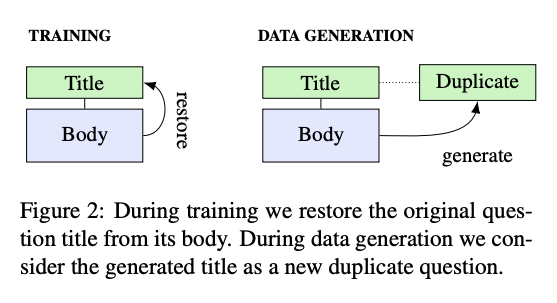
Our first method leverages a question generation (QG) model to generate a large number of duplicates. We train our QG model without labeled instances by restoring a question's title from its body. During data generation, we then consider each generated title as a duplicate of the question's original title. Surprisingly, we find that our QG models can be widely applied as they transfer well across distant domains, e.g., from StackExchange Academia to AskUbuntu.
Training with Title-Body Pairs
Our second method takes this one step further and directly trains models on question title-body pairs. Thereby, the model learns to identify whether a title and body belong to the same or different questions. We show that this approach can be widely applied and yields good results for both duplicate question detection and answer selection.
Abstract
Supervised training of neural models to duplicate question detection in community Question Answering (cQA) requires large amounts of labeled question pairs, which are costly to obtain. To minimize this cost, recent works thus often used alternative methods, e.g., adversarial domain adaptation. In this work, we propose two novel methods: (1) the automatic generation of duplicate questions, and (2) weak supervision using the title and body of a question. We show that both can achieve improved performances even though they do not require any labeled data. We provide comprehensive comparisons of popular training strategies, which provides important insights on how to best train models in different scenarios. We show that our proposed approaches are more effective in many cases because they can utilize larger amounts of unlabeled data from cQA forums. Finally, we also show that our proposed approach for weak supervision with question title and body information is also an effective method to train cQA answer selection models without direct answer supervision.
Bibtex
@inproceedings{rueckle:EMNLP:2019,
title = {Neural Duplicate Question Detection without Labeled Training Data},
author = {R{\"u}ckl{\'e}, Andreas and Moosavi, Nafise Sadat and Gurevych, Iryna},
publisher = {Association for Computational Linguistics},
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019)",
pages = "1607--1617",
year = "2019",
address = "Hong Kong, China",
url = "https://www.aclweb.org/anthology/D19-1171",
doi = "10.18653/v1/D19-1171",
}