Launching AdapterHub: A Framework and Central Repository for Adapters
 We have just open-sourced AdapterHub.ml — a framework and central repository enabling the effortless adaptation of pre-trained transformers such as BERT, RoBERTa, and XLM‑R to new tasks and languages!
We have just open-sourced AdapterHub.ml — a framework and central repository enabling the effortless adaptation of pre-trained transformers such as BERT, RoBERTa, and XLM‑R to new tasks and languages!
Pre-trained transformers have led to considerable advances in NLP, achieving state-of-the-art results across the board. They often contain hundreds of millions of parameters, and thus, sharing and distributing fine-tuned transformer models can be prohibitive. Adapters are a light-weight alternative to full model fine-tuning, consisting of only a tiny set of newly introduced parameters at every transformer layer. During training, the weights of the pre-trained transformer are fixed, which allows us to share the large majority of parameters between tasks. This results in extremely light-weight models (one adapter is around 3MB!). Adapters have been shown to achieve performances comparable to full model fine-tuning. Moreover, they provide elegant ways to share knowledge across multiple tasks more effectively, and we can leverage them for zero-shot cross-lingual transfer.
Before AdapterHub, training, sharing, and re-using adapters has not been straightforward. The reasons are that there exist several different adapter architectures, several ways of composing them, and a wide variety of pre-trained transformers. AdapterHub solves this issue by providing a unified interface to the most recent adapter architectures and composition techniques. Built on top of HuggingFace's popular Transformers library, AdapterHub has access to the most widely used pre-trained transformers.
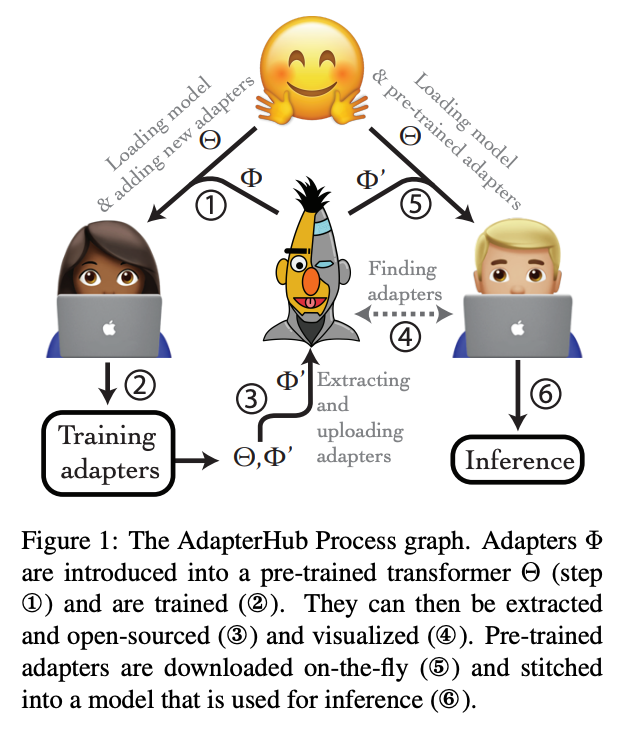
AdapterHub covers the entire lifecycle of adapter training, inference, and sharing by (a) providing an open-source framework, (b) establishing a central repository of pre-trained adapters.
An Open-Source Framework for Adapting Transformers
Our AdapterHub framework is a fork of the popular Transformers library by HuggingFace. Therefore, Researchers can effortlessly integrate AdapterHub in existing experimental code by a drop-in replacement of the original library.
AdapterHub provides researchers with additional methods, e.g., to instantiate adapters in transformers and to freeze/unfreeze their weights. The following code provides a minimal example (this corresponds to figure 2 in our paper):
model = AutoModelWithHeads.from_pretrained('roberta-base')
model.add_adapter("sst-2", AdapterType.text_task)
model.train_adapter(["sst-2"])
...
model.save_adapter("adapters/text-task/sst-2/", "sst-2")
model.add_adapter adds the new adapter weights to the model, here under the name "sst-2".
model.train_adapter indicates that we wish to train the adapter (and only the adapter), thus freezing the pre-trained transformer model weights.
There exist several possible options for configuring adapters, e.g., we can choose among different architectures. Our documentation describes this in greater detail.
After adapter training has been finished, we call model.save_adapter to export the adapter's config and weights.
We can seamlessly load our adapter into the same pre-trained transformer model, which makes it possible to share and open-source trained adapters, e.g., through our central repository.
A Central Repository of Pre-Trained Adapters
AdapterHub is accompanied by a central repository and website to share, find, and reuse pre-trained adapter models. After identifying a suitable adapter, we can simply load it:
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
model.load_adapter("sentiment/sst-2@ukp")
Our repository already contains over 100 adapters across several tasks and languages, see our explore page!
We leverage GitHub's infrastructure, automating the deployment and verification of novel adapters using GitHub actions. Adding new tasks, datasets, and adapters is as simple as creating a single yaml configuration based on one of our example files. Contributions are managed through pull requests to our Hub repository.
For more details, see the AdapterHub lifecycle below and check out our quickstart guide!