COALA: A Neural Coverage-Based Approach for Long Answer Selection with Small Data
Our Contributions:
- We propose COALA, a simple task-specific model for non-factoid answer selection that contains only one layer with learned parameters.
- Our model can be trained with as little as 25 question-answer pairs, demonstrating that it is suitable for few-shot learning.
- COALA scales well to long answers and outperforms several other, more complex models on six datasets from community question answering.
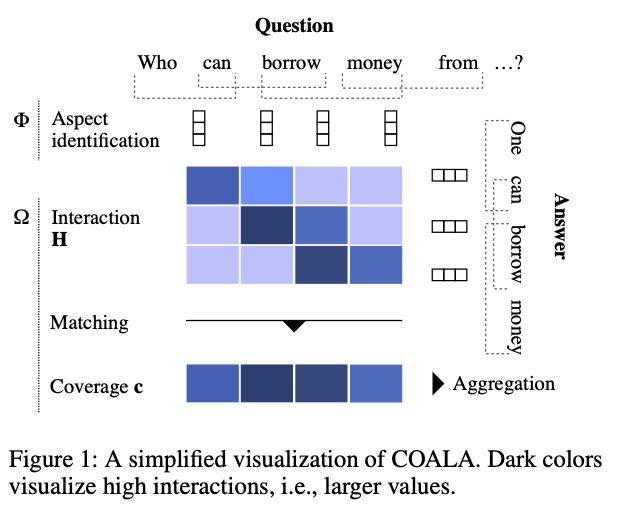
Abstract
Current neural network based community question answering (cQA) systems fall short of (1) properly handling long answers which are common in cQA; (2) performing under small data conditions, where a large amount of training data is unavailable—i.e., for some domains in English and even more so for a huge number of datasets in other languages; and (3) benefiting from syntactic information in the model—e.g., to differentiate between identical lexemes with different syntactic roles. In this paper, we propose COALA, an answer selection approach that (a) selects appropriate long answers due to an effective comparison of all question-answer aspects, (b) has the ability to generalize from a small number of training examples, and (c) makes use of the information about syntactic roles of words. We show that our approach outperforms existing answer selection models by a large margin on six cQA datasets from different domains. Furthermore, we report the best results on the passage retrieval benchmark WikiPassageQA.
Bibtex
@inproceedings{rueckle:AAAI:2019,
title = {{COALA}: A Neural Coverage-Based Approach for Long Answer Selection with Small Data.},
author = {R{\"u}ckl{\'e}, Andreas and Moosavi, Nafise Sadat and Gurevych, Iryna},
publisher = {Association for the Advancement of Artificial Intelligence},
booktitle = {Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI 2019)},
pages = {6932--6939},
month = jan,
year = {2019},
location = {Honolulu, Hawaii, USA},
doi = "10.1609/aaai.v33i01.33016932",
url = "https://aaai.org/ojs/index.php/AAAI/article/view/4671/4549"
}