Improved Cross-Lingual Question Retrieval for Community Question Answering
Our Contributions
- We are the first to study cross-lingual question retrieval in programming cQA, using a combination of machine translation and a monolingual model. We observe that the translation quality strongly influences performance.
- We leverage back-translation to adapt an NMT model to our domains' idiosyncrasies and reveal that this leads to considerable improvements.
- We narrow the gap to a setup with access to an external state-of-the-art commercial MT service by up to 85%.
Improving Cross-Lingual Question Retrieval with Back-Translation
We leverage a standard approach to cross-lingual information retrieval, depicted below (figure 1 of our paper), which is to machine translate the query to our target language (NMT) and then continue with a monolingual question retrieval model for re-ranking (QR).
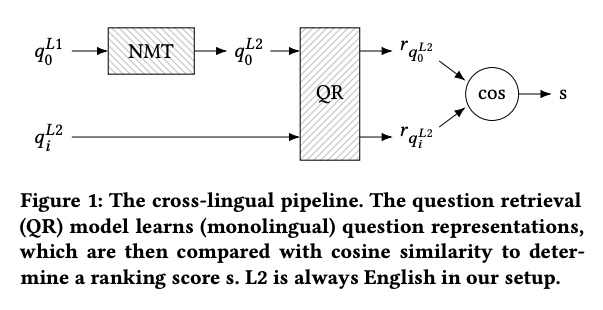
We investigate two adaptations if this approach, which both rely on back-translation (depicted below; table 1 of our paper):
- We adapt a state-of-the-art neural machine translation model to our domains' idiosyncrasies by extending the training corpus with synthetic parallel in-domain sentences from cQA forums. We obtain such sentences by first training an NMT model on out-of-domain data and translate in-domain sentences to our target language with it. We then extend the training corpus with these synthetic parallel sentences and train a new NMT model with this data. This method we use is known as back-translation in machine translation literature.
- We enhance the robustness of a neural question similarity model to common translation errors by adding back-translated texts during training. This time, we translate questions from our source language to the target language and back. This technique is sometimes used in NLP for automatic paraphrasing.

Both adaptations yield considerable improvements and narrow the gap to a setting with an external state-of-the-art commercial MT service by up to 85%.
Abstract
We perform cross-lingual question retrieval in community question answering (cQA), i.e., we retrieve similar questions for queries that are given in another language. The standard approach to cross-lingual information retrieval, which is to automatically translate the query to the target language and continue with a monolingual retrieval model, typically falls short in cQA due to translation errors. This is even more the case for specialized domains such as in technical cQA, which we explore in this work. To remedy, we propose two extensions to this approach that improve cross-lingual question retrieval: (1) we enhance an NMT model with monolingual cQA data to improve the translation quality, and (2) we improve the robustness of a state-of-the-art neural question retrieval model to common translation errors by adding back-translations during training. Our results show that we achieve substantial improvements over the baseline approach and considerably close the gap to a setup where we have access to an external commercial machine translation service (i.e., Google Translate), which is often not the case in many practical scenarios.
Bibtex
@inproceedings{rueckle:WWW:2019,
title = {Improved Cross-Lingual Question Retrieval for Community Question Answering},
author = {R{\"u}ckl{\'e}, Andreas and Swarnkar, Krishnkant and Gurevych, Iryna},
publisher = {ACM},
booktitle = {The World Wide Web Conference (WWW 2019)},
pages = {3179--3186},
year = {2019},
location = {San Francisco, California, USA},
doi = {10.1145/3308558.3313502},
url = {http://doi.acm.org/10.1145/3308558.3313502},
}