Representation Learning for Answer Selection with LSTM-Based Importance Weighting
Our Contributions
- We establish that self-attention is very effective for learning question and answer representations. We infer the importance of text segments without requiring dependent encoding of questions and answers and without cross-attention.
- Our self-attentive approach uses a dedicated BiLSTM component for importance weighting and it allows us to pre-compute the representations of all answers independently from the question.
- Our approach considerably outperforms CNNs and BiLSTMs without attention as well as stacked models. We outperform many standard attention-based models that require learning new answer representations for each question.
Self-Attentive Importance Weigthing
Standard attention-based models suffer from a crucial shortcoming: dependent encoding. Dependent encoding means that models can only learn question and answer representations jointly, i.e., we cannot pre-compute representations of all answers within a large dataset. This is because these models rely on cross-attention, which determines the importance of answer text segments by their similarity or relatedness to the question.
In our work, we address this shortcoming and propose LSTM-Based Importance Weighting (LW). LW uses a separate LSTM component for importance weighting that does not introduce a dependency between question and answer texts. Thus, it can be more efficient at run-time because our model allows us to pre-compute all answer representations before QA inference.
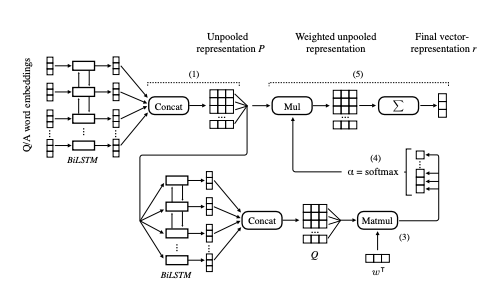
Our experimental results on InsuranceQA demonstrate the effectiveness of LW, which considerably outperforms CNNs, BiLSTMs, stacked models, and different state-of-the-art attention-based models with dependent encoding. Finally, we also show that our approach generalizes well to the factoid answer selection dataset WikiQA.
Abstract
We present an approach to non-factoid answer selection with a separate component based on BiLSTM to determine the importance of segments in the input. In contrast to other recently proposed attention-based models within the same area, we determine the importance while assuming the independence of questions and candidate answers. Experimental results show the effectiveness of our approach, which outperforms several state-of-the-art attention-based models on the recent non-factoid answer selection datasets InsuranceQA v1 and v2. We show that it is possible to perform effective importance weighting for answer selection without relying on the relatedness of questions and answers. The source code of our experiments is publicly available.
Bibtex
@InProceedings{rueckle:2017:IWCS,
title = {Representation Learning for Answer Selection with LSTM-Based Importance Weighting},
author = {R{\"u}ckl{\'e}, Andreas and Gurevych, Iryna},
publisher = {Association for Computational Linguistics},
booktitle = {Proceedings of the 12th International Conference on Computational Semantics (IWCS 2017)},
month = sep,
year = {2017},
location = {Montpellier, France}
}