Concatenated Power Mean Word Embeddings as Universal Cross-Lingual Sentence Representations
Our Contributions
- We propose a hard-to-beat baseline for universal sentence embeddings. We generalize the concept of average word embeddings by (a) concatenating diverse word embeddings that store different kinds of information and (b) by combining different power means that capture more information from the sequence of word embeddings.
- Concatenated power mean word embeddings are training-free and considerably narrow the monolingual gap to state-of-the-art supervised methods such as InferSent.
- We extend the universality of sentence embeddings to the cross-lingual case. Our models substantially outperform many popular sentence embeddings across several classification tasks monolingually and substantially outperform other approaches cross-lingually.
A Hard to Beat Baseline
The figure below shows the average monolingual performance and the dimensionality of the different sentence embedding models that we tested.
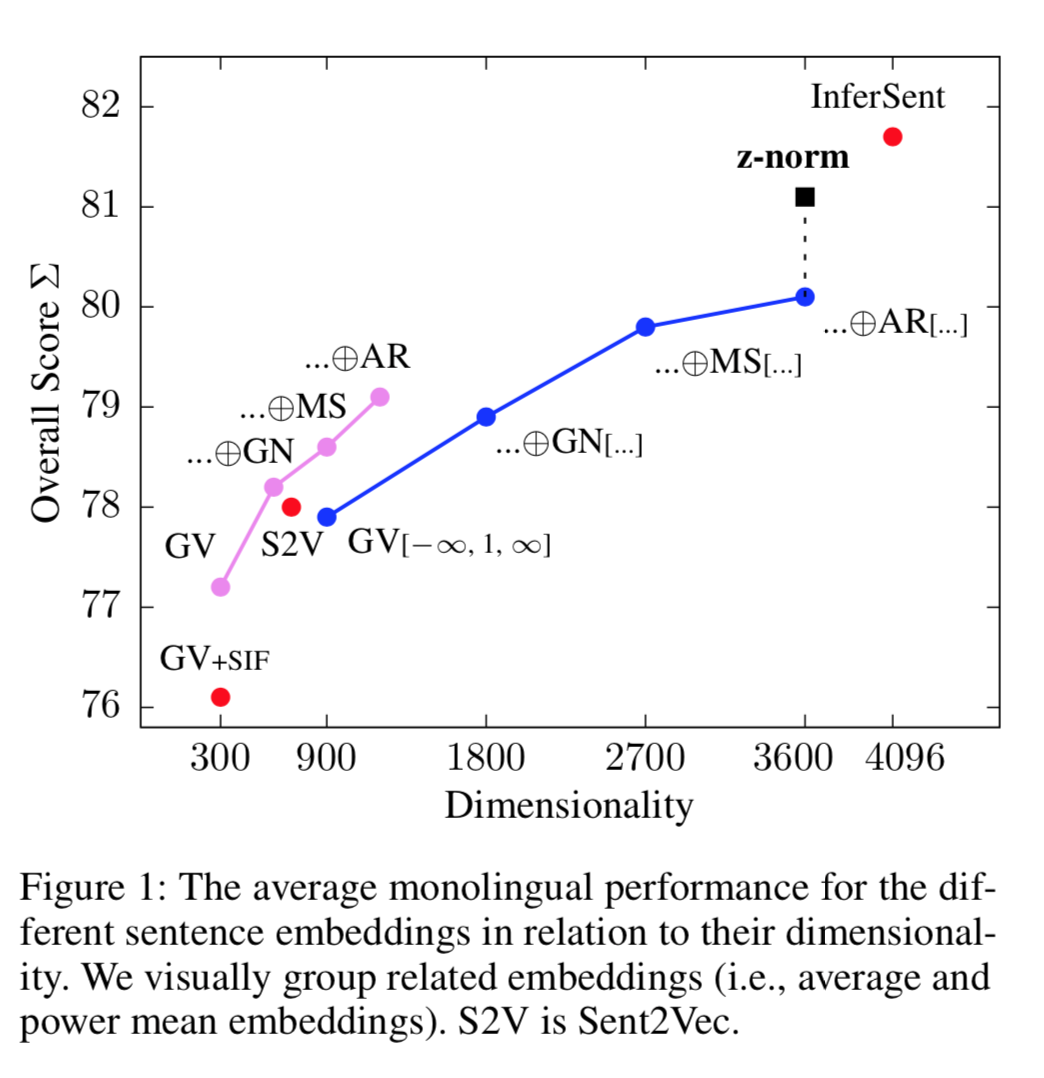
Abstract
Average word embeddings are a common baseline for more sophisticated sentence embedding techniques. However, they typically fall short of the performances of more complex models such as InferSent. Here, we generalize the concept of average word embeddings to power mean word embeddings. We show that the concatenation of different types of power mean word embeddings considerably closes the gap to state-of-the-art methods monolingually and substantially outperforms these more complex techniques cross-lingually. In addition, our proposed method outperforms different recently proposed baselines such as SIF and Sent2Vec by a solid margin, thus constituting a much harder-to-beat monolingual baseline. Our data and code are publicly available.
Bibtex
@article{rueckle-etal-2018-pmeans,
title = {Concatenated Power Mean Word Embeddings as Universal Cross-Lingual Sentence Representations},
author = {R{\"u}ckl{\'e}, Andreas and Eger, Steffen and Peyrard, Maxime and Gurevych, Iryna},
journal = {arXiv},
year = {2018},
url = "https://arxiv.org/abs/1803.01400"
}